Define Data Preprocessing?
Resources & Suggestions
Mains Answer Writing Latest Articles
On: April 18, 2025
Daily Answer Writing Practice Questions (18 April 2025)
Do you agree with the claim that indecision and risk aversion are prevalent issues in Indian bureaucracy? Support your answer with logical reasoning. (150 words) ऐसा कहा जाता है कि भारतीय नौकरशाही में अनिर्णय और जोखिम से बचने की प्रवृत्ति ...
On: April 18, 2025
Comments:
0
Strengthening India’s Cyber Defence
Rising Threats Digital Era Challenges: 2024 marks a significant rise in digital threats, particularly from AI and cyberattacks. Key Issues: Disinformation campaigns. Cyber fraud affecting daily life. Current Major Cyber Threats Ransomware Rampage: Over 48,000 instances of WannaCry ransomware detected ...
On: April 18, 2025
Comments:
0
भारत की साइबर सुरक्षा
बढ़ते खतरे कृत्रिम बुद्धिमत्ता (AI) और साइबर हमले: 2024 में AI और साइबर हमलों के खतरे में वृद्धि। महत्वपूर्ण अवसंरचना पर हमले: डिजिटल हमलों और दुष्प्रचार अभियानों की संभावना बढ़ी है। प्रमुख साइबर खतरें रैनसमवेयर का प्रकोप: 48,000 से अधिक ...
Data Preprocessing is a crucial step in the data analysis and machine learning pipeline, involving the transformation of raw data into a clean and usable format. This process addresses issues such as missing values, noise, and inconsistencies in the data, ensuring that the dataset is suitable for further analysis or model training. Effective data preprocessing improves the accuracy and efficiency of analytical models by providing a solid foundation of high-quality data.
Key steps in data preprocessing include:
In conclusion, data preprocessing is an essential step that ensures the quality and reliability of the data used for analysis and modeling. By addressing data quality issues and transforming the data into a suitable format, preprocessing enables more accurate and efficient analysis. For example, in a customer segmentation project, preprocessing might involve cleaning customer transaction data, normalizing purchase amounts, and encoding categorical features like customer demographics. This processed data would then lead to more precise and actionable insights.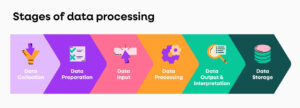
Data preprocessing is a crucial step in the data analysis and machine learning pipeline. It refers to the process of transforming and preparing raw data for further analysis or modeling. The main goals of data preprocessing are to improve the quality, consistency, and suitability of the data for the specific task or algorithm being used.
The key activities involved in data preprocessing include:
Data preprocessing is an important first step in turning random data into actionable information. Eliminate problems such as noise, redundancy, and incompleteness to prepare data for analysis, machine learning prototyping, and other data processing activities
The main objectives of data preprocessing are:
1. Cleaning: Errors, inconsistencies and inaccuracies are removed from the data to ensure quality.
2. Conversion: This stage converts the data into a format that is appropriate for the planned research in terms of size, structure and methodology.
3.Integration: Combining data from multiple sources produces homogeneous and complete data.
The purpose of data preprocessing is to improve data quality, increase data accuracy, and prepare data for subsequent analysis or processing. By ensuring that data is properly organized, accurate, and complete, data prioritization maximizes the success of data-driven businesses.
In summary, data preprocessing transforms raw data into a clean and organized data set, ready for further analysis, modeling, or other application tasks. Proper implementation is essential for data-driven businesses to produce reliable and meaningful results.