Natural Language Processing (NLP) is a subfield of artificial intelligence (AI) focused on enabling computers to understand, interpret, and generate human language. Key Components of NLP: Text Processing: Tokenization: Breaking text into smaller units, like words or sentences. Lemmatization/StemmingRead more
Natural Language Processing (NLP) is a subfield of artificial intelligence (AI) focused on enabling computers to understand, interpret, and generate human language.
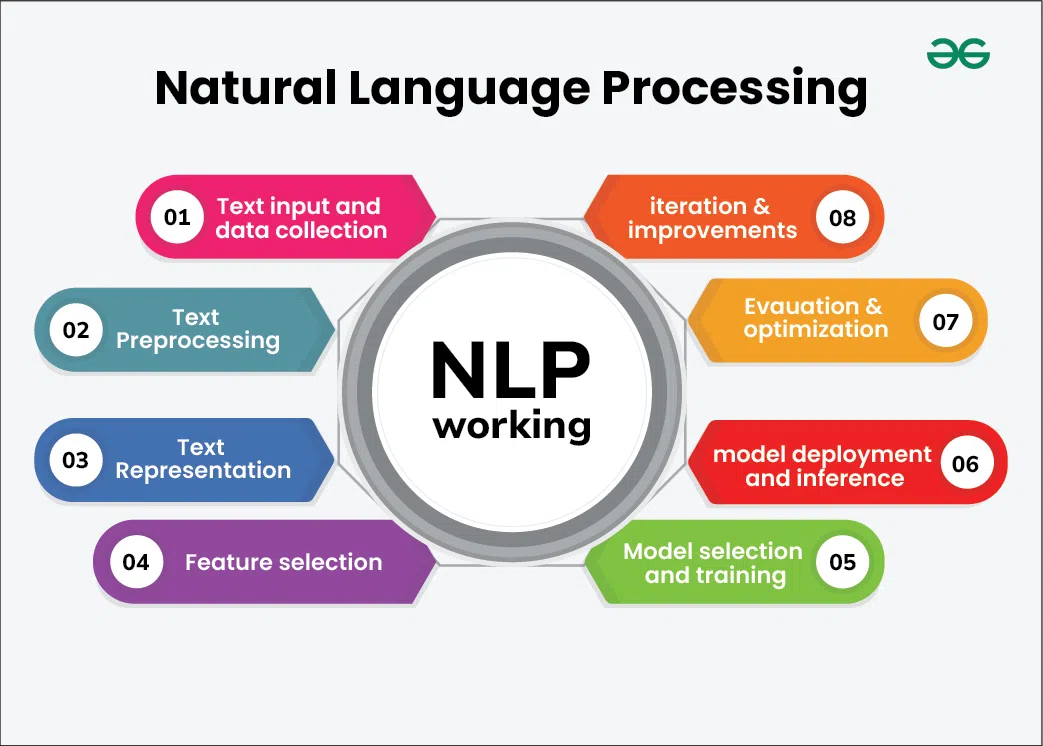
Key Components of NLP:
- Text Processing:
- Tokenization: Breaking text into smaller units, like words or sentences.
- Lemmatization/Stemming: Reducing words to their base or root forms.
- Syntax Analysis:
- Parsing: Analyzing the grammatical structure of sentences.
- Part-of-Speech Tagging: Identifying parts of speech (nouns, verbs, adjectives, etc.) in text.
- Semantics:
- Named Entity Recognition (NER): Identifying entities like names, dates, and places.
- Word Sense Disambiguation: Determining word meaning based on context.
- Pragmatics:
- Understanding context and intended meaning, including implied or indirect meanings.
Applications of NLP:
- Machine Translation: Translating text between languages (e.g., Google Translate).
- Sentiment Analysis: Determining the emotional tone of text (e.g., analyzing social media posts).
- Chatbots and Virtual Assistants: Enabling conversational agents like Siri and Alexa to interact in natural language.
- Information Retrieval: Enhancing search engines for accurate query responses.
- Text Summarization: Automatically generating concise summaries of larger texts.
- Speech Recognition: Converting spoken language into text.
Challenges in NLP:
- Ambiguity: Words and sentences can have multiple meanings.
- Context Understanding: Capturing the context in which words are used.
- Cultural and Linguistic Variations: Handling different languages and dialects.
NLP is rapidly evolving, significantly advancing AI and transforming human-machine interaction. It encompasses a range of techniques and applications that make human language accessible to computers, improving tasks from translation and sentiment analysis to virtual assistance and information retrieval.
See less
Q-learning is a model-free reinforcement learning algorithm used to find the optimal action-selection policy for a given finite Markov decision process. It uses a Q-table where each entry corresponds to a state-action pair, and the value indicates the expected future rewards of taking that action frRead more
Q-learning is a model-free reinforcement learning algorithm used to find the optimal action-selection policy for a given finite Markov decision process. It uses a Q-table where each entry corresponds to a state-action pair, and the value indicates the expected future rewards of taking that action from that state. The algorithm updates the Q-values iteratively using the Bellman equation: Q(s,a)←Q(s,a)+α(r+γmaxa′Q(s′,a′)−Q(s,a)) where is the current state, is the action taken, is the reward received, is the next state, is the learning rate, and is the discount factor.
The SARSA (State-Action-Reward-State-Action) algorithm is also a model-free reinforcement learning method but follows an on-policy approach. It updates the Q-values based on the action actually taken in the next state: Q(s,a)←Q(s,a)+α(r+γQ(s′,a′)−Q(s,a)) where s is the current state, is the current action, is the reward, is the next state, and is the next action chosen according to the current policy. SARSA emphasizes learning the action-value function based on the policy being followed, incorporating both exploration and exploitation during learning.
See less